
One of the most difficult questions for self-driving cars concerns their safety: How can we determine whether a particular self-driving car model is safe? The most popular answer to this question is based on a straightforward application of statistics and leads to conclusions such as that “…fully autonomous vehicles would have to be driven hundreds of millions of miles and sometimes hundreds of billions of miles to demonstrate their reliability…”. This statement comes from a recent RAND report by Nidri Kalra and Susan Paddock on the topic. Unfortunately, these statements are untenable in this form because the statistical argument contains major oversights and mistakes, which we will point out in the following.
7.1 Failure rate estimation
![]() The argument is usually presented as a problem of failure rate estimation where observed failures (accidents involving self-driving cars) are compared against a known failure rate (accident rates of human drivers). Accidents are modeled as discrete, independent and random events that are determined by a (statistically constant) failure rate. The failure rate for fatal accidents can be calculated by dividing the number of accidents with fatalities by the number of vehicle miles traveled. If we consider the 32,166 crashes with fatalities in traffic in the US in 2015 and relate them to the 3.113 billion miles which motor vehicles traveled, then the failure rate is 32,166 / 3.113 billion = 1.03 fatalities per 100 million miles. The probability that a crash with fatality occurs on a stretch of 1 mile is extremely low (0,0000010273%) and the opposite, the success rate, the probability that no accident with fatality occurs on a stretch of 1 vehicle-mile-traveled (VMT) is very high (99,999998972%). By observing cars driving themselves, we can obtain estimates of their failure rate. The confidence that such estimates reflect the true failure rate increases with the number of vehicle miles traveled. Simple formulas for binomial probability distributions can be used to calculate the number of miles which need to be driven without failure to reach a certain confidence level: 291 million miles need to be driven by a self-driving car without fatality to be able to claim with a 95% confidence level that self-driving cars are as reliable as human drivers. This is nearly three times the distance between fatalities that occur during human driving. If we relax the required confidence level to 50%, then at least 67 million miles need to be driven without fatality before we can be confident that self-driving cars are safe. Although this calculation is simple most authors – including the authors of the RAND report – use the wrong measures. Instead of dividing the number of crashes involving fatalities (32,166) by VMT, they divide the number of fatalities (35,091) by VMT. This overstates the failure rate of human drivers because a single accident may lead to multiple fatalities and the number of fatalities per fatal accident may depend on many factors other than the reliability of the driver.
The argument is usually presented as a problem of failure rate estimation where observed failures (accidents involving self-driving cars) are compared against a known failure rate (accident rates of human drivers). Accidents are modeled as discrete, independent and random events that are determined by a (statistically constant) failure rate. The failure rate for fatal accidents can be calculated by dividing the number of accidents with fatalities by the number of vehicle miles traveled. If we consider the 32,166 crashes with fatalities in traffic in the US in 2015 and relate them to the 3.113 billion miles which motor vehicles traveled, then the failure rate is 32,166 / 3.113 billion = 1.03 fatalities per 100 million miles. The probability that a crash with fatality occurs on a stretch of 1 mile is extremely low (0,0000010273%) and the opposite, the success rate, the probability that no accident with fatality occurs on a stretch of 1 vehicle-mile-traveled (VMT) is very high (99,999998972%). By observing cars driving themselves, we can obtain estimates of their failure rate. The confidence that such estimates reflect the true failure rate increases with the number of vehicle miles traveled. Simple formulas for binomial probability distributions can be used to calculate the number of miles which need to be driven without failure to reach a certain confidence level: 291 million miles need to be driven by a self-driving car without fatality to be able to claim with a 95% confidence level that self-driving cars are as reliable as human drivers. This is nearly three times the distance between fatalities that occur during human driving. If we relax the required confidence level to 50%, then at least 67 million miles need to be driven without fatality before we can be confident that self-driving cars are safe. Although this calculation is simple most authors – including the authors of the RAND report – use the wrong measures. Instead of dividing the number of crashes involving fatalities (32,166) by VMT, they divide the number of fatalities (35,091) by VMT. This overstates the failure rate of human drivers because a single accident may lead to multiple fatalities and the number of fatalities per fatal accident may depend on many factors other than the reliability of the driver.
7.2 Correlations matter!
Most authors duly proceed to calculate the failure rate for other types of incidents: The 1.715 million crashes with personal injury lead to a failure rate (including fatalities) of 56 failures per 100 million VMT. At a confidence level of 95% (50%) fully autonomous vehicles must travel 5.4 (1.2) million miles without failure. If we add the 4.387 million police-reported crashes without injury this leads to a failure rate of 201 failures per 100 million VMT. To reach a confidence level of 95% (50%) fully autonomous vehicles must travel 1.5 million (344,000) miles without failure. The RAND report points out that many accidents are not reported. The relationship of actual to reported accidents is not clear; some scientific studies have shown that it may be in the range between 2 and 4. The US Census uses the factor of 2 to estimate the number of accidents from the number of crashes. If we take the census estimate, then self-driving vehicles would have to travel only 745,000 (172,000) miles without accident at a confidence level of 95% (50%) to conclude that self-driving cars are as reliable as cars driven by humans.
If we consider different types of failures, not just accidents with fatalities, then the number of miles which need to be driven drops greatly. This brings us to the largest flaw in the statistical argument: the probability distributions of accidents with fatalities, accidents with personal injuries, and other accidents are correlated, they are not independent! A car that is much better at avoiding non-fatal accidents than human drivers is also likely to be better than human drivers at avoiding fatal accidents! A self-driving car that has a high rate of fatal crashes will also have a high rate of non-fatal crashes and vice versa. Because we also have other measurable failure rates besides the fatality rate such as the crash rate, the personal injury rate and the overall accident rate, we can gain insights about the level of reliability of self-driving cars much much earlier than the hundreds of millions of miles needed for building confidence by focusing just on the fatality rate.
One could object that the relationship between the different types of failure rates is not known. Self-driving cars will certainly have a different correlation between their various failure rates than human drivers. But it is very hard to find plausible arguments why self-driving cars might have a property damage or personal injury accident rate much lower than human drivers but could at the same time have a fatality rate that is significantly higher than human drivers.
Therefore there is no reason why a comparison of the reliability of self-driving cars and human drivers should primarily focus on the fatality rate. We should be glad that fatal accidents are not that frequent which immediately means that enormous numbers of miles need to be driven by self-driving cars if we could only use this measure to estimate the safety of self-driving cars. But many other statistical measures (crash rate, personal injury rate, accident rate etc. are available and much easier to measure. Before we look into these measures in more detail further below, we need to point out additional shortcomings of the current statistical argument:
7.3 Choosing the right independent variable
The number of vehicle miles traveled may not be the best unit against which to measure accidents. The quickest way to accumulate test miles is to drive on highways. But highway driving is safer than driving on many other streets. Of the 3.148 billion vehicle miles traveled in the US in 2015 about a quarter occurred on rural or urban interstate highways; however only about 12% of fatal accidents occurred on these roads. Because the average speed varies between different road types, driving time may be a better basis for measuring failure rate than driving distance. It is well known that urban driving is the most difficult scenario for self-driving cars (and probably also for human drivers, although this may be reflected more in the crash statistics than in the fatality statistics because average speeds are lower). Because average speeds differ greatly, using time instead of distance will have a significant effect on the reliability rates and might significantly reduce the number of test miles (while also reducing the incentive for self-driving car companies to accumulate test miles on what many regards as the “easiest” roads – interstate highways!).
Conceptually, driving is most difficult, when the environment changes, when actions need to be taken. Just driving straight is not much of a challenge. We should look for other measures that come closer to the complexity of driving and the risks associated with driving. A simple proxy that would be easy to calculate for self-driving cars and not impossible to estimate for human driving statistics could be the number of intersections which are passed. This measure contains both an element of distance and risk because a large percentage of accidents occur at intersections. Therefore the number of intersections passed might also be a good independent variable against which to measure reliability rates.
Just using overall miles driven and not differentiating between the different types of environments which the cars are driven in and not differentiating between the risk levels of the routes is intellectually lazy. Over the years we have collected enormous amounts of information about traffic accidents and the situations in which they occur; we need to carefully go through this data and develop much more refined measures for understanding and assessing the reliability of human as well as autonomous driving.
7.4 Averaging human driving capabilities?
Which brings us to the next problem of our simple statistical model: the reference which we use to determine whether a self-driving car is safe. We have abundant statistics about the fatality and crash rates of human drivers but are these useful measures? Do we really want to include all the accidents caused by drunk drivers, tired drivers, texting drivers, recklessly speeding drivers in this comparison? Can such accidents even remotely be included in the standard against which we want to measure the reliability of self-driving cars? Who would be we willing to tolerate similar levels of errors caused by algorithms? If we think this through, it should become obvious that no society would tolerate self-driving cars that have levels of accidents similar to human drivers. These cars – that never tire, never drink, never take their attention off the road – would have to make other grave errors at much higher rates than humans which our societies would never be prepared to forgive. Although the big averages of human-driven fatality and crash rates are easy to obtain, they are not the standard against which we should measure the reliability of self-driving cars. Instead we will need to carefully craft our expectations and requirements concerning the level of safety which self-driving cars should exhibit into a set of measures based on all that we know about the problem and risk of driving in general, not just of human driving. A real effort is required to build such measures and statistics and the enormous body of research related to safety can be a basis.
7.5 Much more detailed models of driving risk needed
We need to go far beyond the established human-centric look at the problem of driving. We need scientists who build detailed risk models of driving which leverage our accidents statistics and determine the contribution of road structure, congestion levels, weather and many other factors on the risk of driving which can then be used to build reference metrics for the behavior of self-driving cars. We should not let the companies building self-driving cars create these measures all on their own but we need their input because as they develop and test their cars they also gain many deep insights into the structure and risks of the driving problem.
It is a major oversight of the Google team and other commercial developers of self-driving cars that they have not made an effort to show the world better models and metrics for evaluating the safety of driving. Google’s monthly reports must be lauded as a level of transparency that is important and that no other developers of self-driving cars (Daimler, Ford, Volkswagen, Nissan, Volvo, Tesla, EasyMile, Uber, Zoox, Baidu, Delphi, and many others) have provided yet. But Google should use their monthly reports not just to provide a mileage count (a number that all readers can misinterpret too easily) but also to educate the readers that there are better ways of measuring the safety levels of a self-driving car. Without giving too much away they could, for example, break their mileage numbers down by road type (at least: city, highway (both interstate and rural), rural). This would help turn the focus of the discussion on the safety of self-driving cars away from a single, overall number. They could also publish a complexity metric which indicates the average complexity of the environment their vehicles have driven through or the overall distribution of complexity encountered during their test drives. Just publishing the number of intersections passed (see above) would also help change the nature of the discussions on assessing the safety of self-driving cars. The public should expect that all companies providing self-driving cars publish metrics about the safety of their cars during testing and that these metrics should go significantly beyond just distance driven. The emerging self-driving car industry should collaborate on putting together such metrics (rather than wait for the regulators to ask for them).
7.6 Reliability of self-driving cars is not a constant
Another key problem of the simple statistical argument needs to be raised: unlike the usual failure rate scenarios, the reliability rate of a self-driving car model can not be regarded as a constant. It changes, improves, over time; and it has some very unusual properties: Self-driving cars can be placed on the road in such a way that a software defect present in all instances of a car model can – upon detection in one instance – be removed from all instances. Unlike in the manufacture of goods where batches are tested to detect design and manufacturing problems, it is possible to remove the defect not just in batches going through the manufacturing process in the future but also in those batches that have already been released to the client! This is a fundamental difference! Let us assume that the developer of a self-driving car model releases 1000 cars in a well-managed fleet of self-driving cars and operates them on public roads. The developer has tested the model strenuously over several hundred thousand miles and has performed additional staged tests on test-tracks and run the cars through millions of miles of traffic in a simulator. The fleet quickly accumulates miles and a crash occurs. This changes the estimate of the failure rate. If this new estimate does not exceed the required minimum failure rate for self-driving cars, then the cars can remain in service. The developers will improve their algorithms to handle the problem situation and deploy the fix to all cars on the road: The car model’s failure rate (which is not directly observable) is no longer the same. The simple statistical model does not take into account that there is a feedback loop in the failure rate which tends to lower the failure rate with every failure that is encountered.
On the other hand, when a crash occurs, this could also raise the estimated failure rate above the minimum failure rate and indicate that the car model is not suitable for public use. All deployed cars could then be grounded immediately, thus instantly preventing further damage. This is very different from other physical products, such as a medicine or a bicycle where any flaw detected after releasing such products to the consumer will occur again and again because recalls of conventional faulty products are very difficult. This does not mean that we should relax the criteria for deploying self-driving cars. However we need to recognize that we can not simply transfer established reasoning about product failure modes and their consequences to the domain of self-driving cars; the standard statistical modeling approach to this problem is not quite appropriate.
We need to develop a more refined model for estimating the safety of self-driving cars where we account for the unique properties of the problem: there are different types of incidents which indicate failures of different magnitude; we know that the reliability of these cars increases somewhat predictably over time, that models with evidence of too high a failure rate can be grounded immediately, and we know that cars driven by humans also produce accidents.
Most of those worried about the safety of self-driving cars tend to overlook that the problem is dual sided: We need to avoid two cases:
a) That we consider self-driving cars safe and release them to the public although in reality they are not safe enough yet and
b) that we consider self-driving cars unsafe and don’t release them to the public although they are safe.
In case a) self-driving cars will cause damage because people relying on their safety will use them. In case b) damage will be caused because people who would have used a self-driving car are now driving themselves.
Thus the problem of determining the reliability of self-driving car safety is more complex than the usual problems where statistical failure rate estimation is applied. More variables and the dynamic dual-sided nature of the problem need to be taken into account. It is time that more elaborate models are developed!
7.7 Intuitions about human driving capability
Before we close, we need to point out two more issues: Our intuitions concerning the safety of self-driving cars may be clouded by the assumptions that we understand the problem of driving well and that overall we are good drivers. This may not be the case as the following thought example shows:
Assume that we have a set of human drivers who all have exactly the same driving capability and share one trait: they randomly take their attention off the road in front of the car for a brief interval of just half of a second every 10 minutes (which translates to a probability of 0.5 / 10 * 60 = 0.083%). Then assume that a certain potentially difficult problem arises directly in front of the cars in a half-second interval with a probability of once per hour (=0.014%). For example, a car in front unexpectedly steps on the brakes. In most of the cases, the driver reacts immediately, masters the safety-critical situation and nothing happens. But some drivers will be caught in exactly that short interval where they are not paying attention. They can’t react in time and an accident results. The probability that this happens is quite low (0.083% * 0.014% or about 1 in 8 million, or once every 1100 hours of driving) but it will happen from time to time. Although we know that all of these drivers drive equally well, the small minority of drivers with an accident will be regarded as poor drivers while all the others will be proud of their spotless driving record. They don’t realize that they were just lucky!
Chance (or luck) may play a larger role in human driving than we like to think. That more accidents don’t happen might not be so much due to the great capabilities of human drivers but to the relatively low frequency of difficult, unexpected situations. For example, if a car is stopped in the right lane of a highway (lights not flashing), it may not take long – even with good visibility – until someone barrels into it. Fortunately such situations occur rarely and – knowing the danger – people will make an effort to secure the site when such situations occur.
7.8 Safety-critical situations, not just accidents
Thus we need much more refined models of driving risk. Accidents form the basis for our official statistics but accidents are only the tip of the iceberg, as the graphic below shows. Accidents are the outcome of safety-critical situations which have gone wrong. The graphic shows a simple model where driving behavior combined with external factors such as poor road conditions, technical defects, obstacles etc. lead to safety-critical situations. Fortunately, most of these safety-critical situations don’t lead to accidents. The percentages next to some of the factors are from the National Crash Causation Survey and relate to the relative frequency that this factor is identified as first factor leading to an accident.
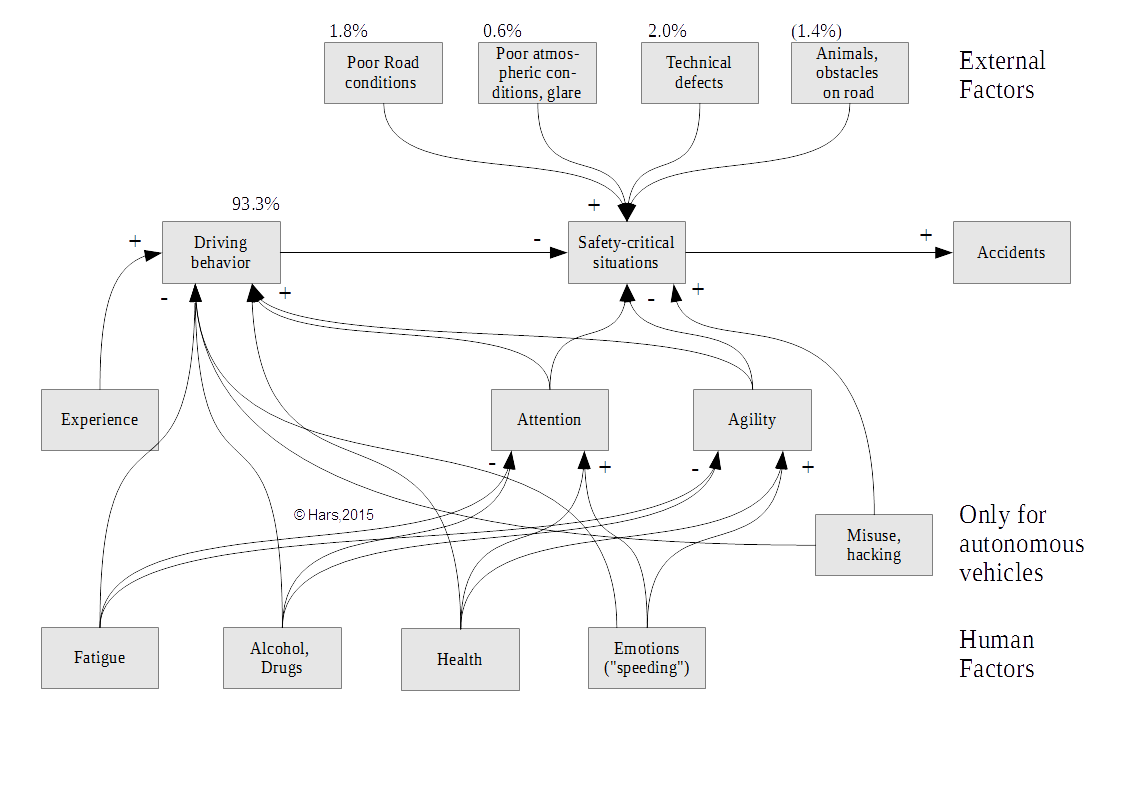
The graphic shows that with more than 93%, driving behavior is a leading factor for fatal traffic accidents. But it also highlights a major difference between human drivers and self-driving cars. With human drivers the focus is on accidents. With self-driving cars, the focus shifts to safety critical situations. Any minute mistake of a self-driving car is cataloged and evaluated, long before any accident happens. When a human driver slightly swerves out of the lane, nobody is concerned (unless an accident happens); however, when a self-driving car does not properly stay in its lane, then this is – rightly – treated as a defect. The same happens when a self-driving car does not give the right of way to other cars etc. Thus we should not just use accident statistics to compare the reliability of human drivers and self-driving cars, we should compare their driving behavior on the frequency of entering safety-critical situations. This is easy to measure for self-driving cars but requires more effort on the side of human driving. Fortunately with the advances in self-driving car technology we now have the means to collect and analyze large amounts of video feeds of actual human driving and determinew safety critical situations and driver behavior.
7.9 Conclusion
In summary, this article shows that the idea that self-driving cars need to drive hundreds of millions of miles before we can be convinced that they are safe is full of flaws. It is misleading to just focus on fatality rates where many other correlated measures for reliability are available that are easier to measure. It is wrong to focus primarily on accidents; the focus should rather be placed on the avoidance of safety-critical situations. Our intuitions related to our own capabilities as a driver may be wrong. Luck may be more important than we like to admit to ourselves. We also need to realize that the reliability of a self-driving car model changes over time and that the damage potential of self-driving cars found to be defective after release to the public is very different from and much smaller than conventional defective products which are hard to recall. Self-driving cars can be effectively and instantly grounded!
Finally, anybody concerned with the safety of self-driving cars needs to consider the dual sided nature of the problem. Not only do we need to avoid self-driving cars being released to the public too early. Because the alternative (human driving) is not safe at all, there is a real risk to releasing self-driving cars too late to the public which will also lead to many traffic deaths that could have been avoided. Almost none of the regulators and safety advocates acknowledge this admittedly very difficult aspect of the regulatory decision problem at all.
It is time to change the discourse on the reliability of self-driving cars and to collaborate to build better, much more refined models of driving and driving risk – both for human drivers and for self-driving cars.